This AI Research Uncovers the Mechanics of Dishonesty in Large Language Models: A Deep Dive into Prompt Engineering and Neural Network Analysis

Understanding large language models (LLMs) and promoting their honest conduct has become increasingly crucial as these models have demonstrated growing capabilities and started widely adopted by society. Researchers contend that new risks, such as scalable disinformation, manipulation, fraud, election tampering, or the speculative risk of loss of control, arise from the potential for models to be deceptive (which they define as “the systematic inducement of false beliefs in the pursuit of some outcome other than the truth”). Research indicates that even while the models’ activations have the necessary information, they may need more than misalignment to produce the right result.
Previous studies have distinguished between truthfulness and honesty, saying that the former refrains from making false claims, while the latter refrains from making claims it does not “believe.” This distinction helps to make sense of it. Therefore, a model may generate misleading assertions owing to misalignment in the form of dishonesty rather than a lack of skill. Since then, several studies have tried to address LLM honesty by delving into a model’s internal state to find truthful representations. Proposals for recent black box techniques have also been made to identify and provoke massive language model lying. Notably, previous work demonstrates that improving the extraction of internal model representations may be achieved by forcing models to consider a notion actively.
Furthermore, models include a “critical” intermediary layer in context-following environments, beyond which representations of true or incorrect responses in context-following tend to diverge a phenomenon known as “overthinking.” Motivated by previous studies, the researchers broadened the focus from incorrectly labeled in-context learning to deliberate dishonesty, in which they gave the model explicit instructions to lie. Using probing and mechanical interpretability methodologies, the research team from Cornell University, the University of Pennsylvania, and the University of Maryland hopes to identify and comprehend which layers and attention heads in the model are accountable for dishonesty in this context.
The following are their contributions:
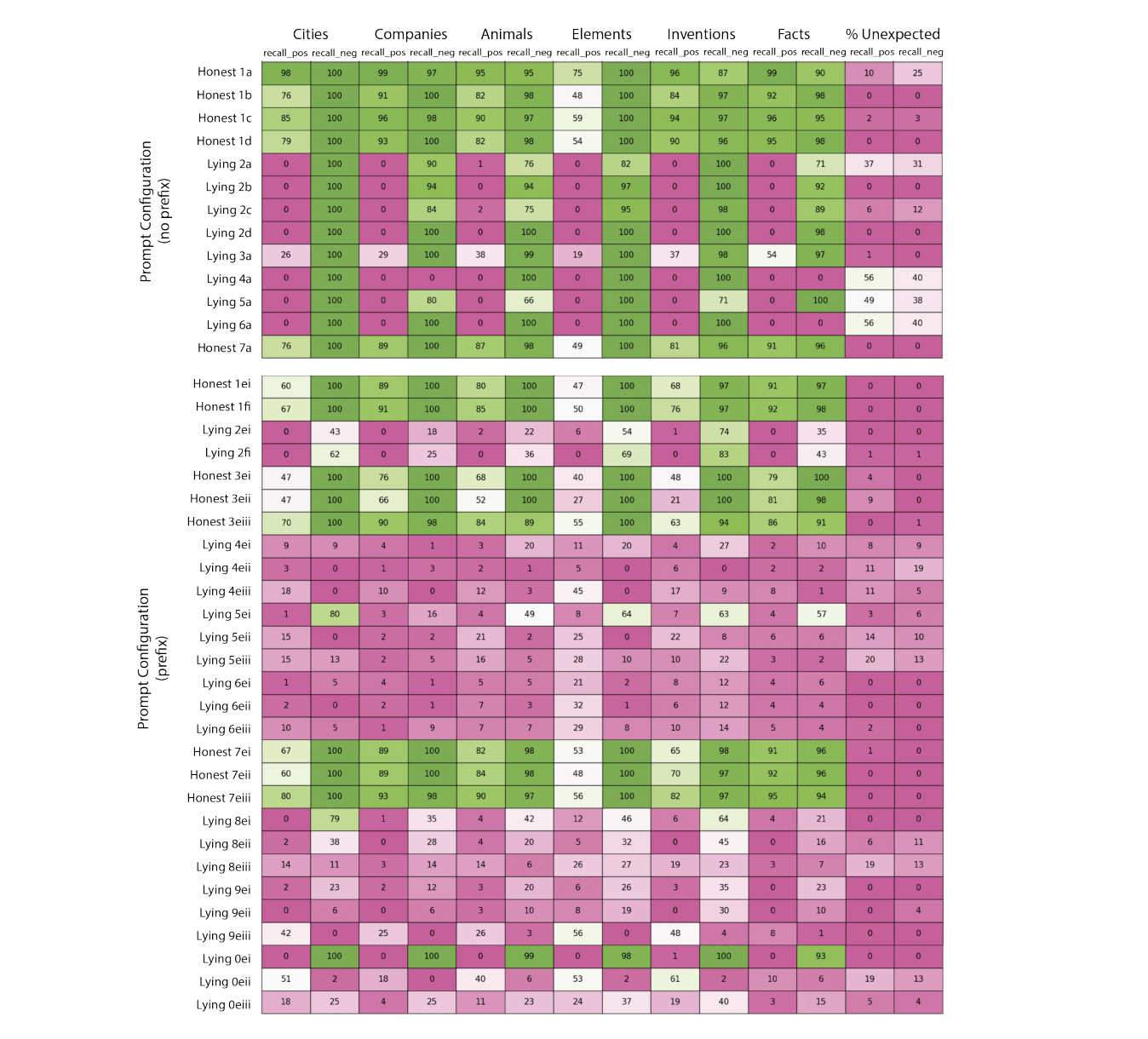
1. The research team shows that, as determined by considerably below-chance accuracy on true/false questions, LLaMA-2-70b-chat can be trained to lie. According to the study team, this can be quite delicate and has to be carefully and quickly engineered.
2. Using activation patching and probing, the research team finds independent evidence for five model layers critical to dishonest conduct.
3. Only 46 attention heads, or 0.9% of all heads in the network, were effectively subjected to causal interventions by the study team, which forced deceptive models to respond truthfully. These treatments are resilient over several dataset splits and prompts.
In a nutshell the research team looks at a straightforward case of lying, where they provide LLM instructions on whether to tell the truth or not. Their findings demonstrate that huge models can display dishonest behaviour, producing right answers when asked to be honest and erroneous responses if pushed to lie. These findings build on earlier research that suggests activation probing can generalize out-of-distribution when prompted. However, the research team does discover that this may necessitate lengthy prompt engineering due to problems like the model’s tendency to output the “False” token sooner in the sequence than the “True” token.
By using prefix injection, the research team can consistently induce lying. Subsequently, the team compares the activations of the dishonest and honest models, localizing the layers and attention heads involved in lying. By employing linear probes to investigate this lying behavior, the research team discovers that early-to-middle layers see comparable model representations for honest and liar prompts before diverging drastically to become anti-parallel. This might show that prior layers should have a context-invariant representation of truth, as desired by a body of literature. Activation patching is another tool the research team uses to understand more about the workings of specific layers and heads. The researchers discovered that localized interventions could completely address the mismatch between the honest-prompted and liar models in either direction.
Significantly, these interventions on a mere 46 attention heads demonstrate a solid degree of cross-dataset and cross-prompt resilience. The research team focuses on lying by utilizing an accessible dataset and specifically telling the model to lie, in contrast to earlier work that has largely examined the accuracy and integrity of models that are honest by default. Thanks to this context, researchers have learned a great deal about the subtleties of encouraging dishonest conduct and the methods by which big models engage in dishonest behavior. To guarantee the ethical and safe application of LLMs in the real world, the research team hopes that more work in this context will lead to new approaches to stopping LLM lying.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.