This AI Research from China Introduces Infinite-LLM: An Efficient Service for Long Context LLM that Utilizes a Novel Distributed Attention Algorithm Called DistAttention and a Distributed KVCache Management Mechanism

The field of natural language processing has been transformed by the advent of Large Language Models (LLMs), which provide a wide range of capabilities, from simple text generation to sophisticated problem-solving and conversational AI. Thanks to their sophisticated architectures and immense computational requirements, these models have become indispensable in cloud-based AI applications. However, deploying these models in cloud services presents unique challenges, particularly in handling auto-regressive text generation’s dynamic and iterative nature, especially for tasks involving long contexts. Traditional cloud-based LLM services often need more efficient resource management, leading to performance degradation and resource wastage.
The primary issue lies in the dynamic nature of LLMs, where each newly generated token is appended to the existing text corpus, forming the input for recalibration within the LLM. This process requires substantial and fluctuating memory and computational resources, presenting significant challenges in designing efficient cloud-based LLM service systems. Current systems, such as PagedAttention, have attempted to manage this by facilitating data exchange between GPU and CPU memory. However, these methods are limited by their scope, as they are restricted to the memory within a single node and thus cannot efficiently handle extremely long context lengths.
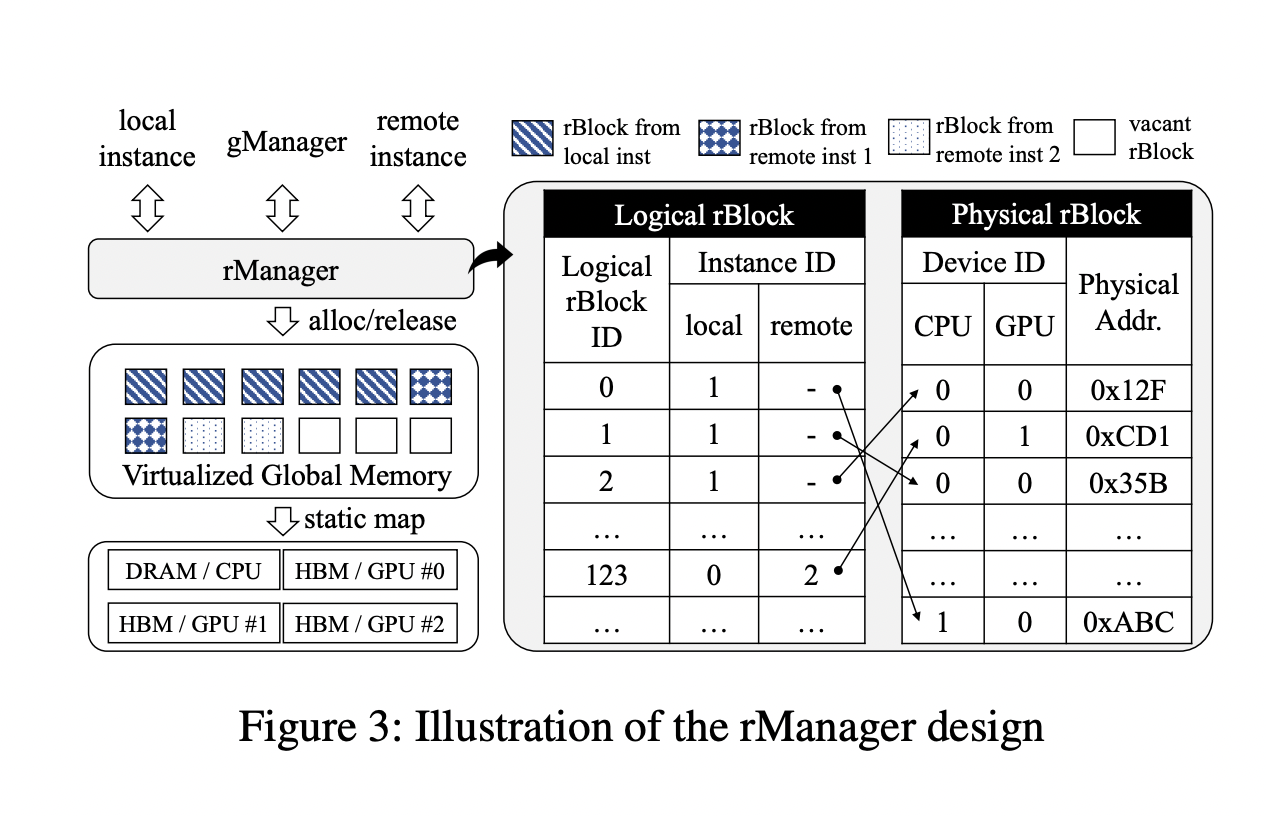
In response, the Ali Baba Group and the Shanghai Jiao Tong University researchers introduce an innovative distributed attention algorithm, DistAttention, which segments the Key-Value (KV) Cache into smaller, manageable units, enabling distributed processing and storage of the attention module. This segmentation efficiently handles exceptionally long context lengths, avoiding the performance fluctuations typically associated with data swapping or live migration processes. The paper proposes DistKV-LLM, a distributed LLM serving system that dynamically manages KV Cache and orchestrates all accessible GPU and CPU memories across the data center.
DistAttention breaks down traditional attention computation into smaller units called macro-attentions (MAs) and their corresponding KV Caches (rBlocks). This approach enables independent model parallelism strategies and memory management for attention layers versus other layers within the Transformer block. DistKV-LLM excels in managing these KV Caches, coordinating memory usage efficiently among distributed GPUs and CPUs throughout the data center. When an LLM service instance faces a memory deficit due to KV Cache expansion, DistKV-LLM proactively borrows supplementary memory from less burdened instances. This intricate protocol facilitates efficient, scalable, and coherent interactions among numerous LLM service instances running in the cloud, enhancing the overall performance and reliability of the LLM service.
The system exhibited significant improvements in end-to-end throughput, achieving 1.03-2.4 times better performance than existing state-of-the-art LLM service systems. It also supported context lengths up to 219 times longer than current systems, as evidenced by extensive testing across 18 datasets with context lengths up to 1,900K. These tests were conducted in a cloud environment with 32 NVIDIA A100 GPUs in configurations from 2 to 32 instances. The enhanced performance is attributed to DistKV-LLM’s ability to orchestrate memory resources across the data center effectively, ensuring high-performance LLM service adaptable to a broad range of context lengths.
This research offers a groundbreaking solution to the challenges faced by LLM services in cloud environments, especially for long-context tasks. The DistAttention and DistKV-LLM systems represent a significant leap forward in addressing the critical issues of dynamic resource allocation and efficient memory management. This innovative approach paves the way for more robust and scalable LLM cloud services, setting a new standard for deploying large language models in cloud-based applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Efficient Deep Learning, with a focus on Sparse Training. Pursuing an M.Sc. in Electrical Engineering, specializing in Software Engineering, he blends advanced technical knowledge with practical applications. His current endeavor is his thesis on “Improving Efficiency in Deep Reinforcement Learning,” showcasing his commitment to enhancing AI’s capabilities. Athar’s work stands at the intersection “Sparse Training in DNN’s” and “Deep Reinforcemnt Learning”.