DiNADO: An Improved Parameterization of NADO for Superior Convergence and Global Optima in Fine-Tuning

Large pre-trained generative transformers have demonstrated exceptional performance in various natural language generation tasks, using large training datasets to capture the logic of human language. However, adapting these models for certain applications through fine-tuning poses significant challenges. The computational efficiency of fine-tuning depends heavily on the model size, making it costly for researchers to work on large models. The fine-tuning on smaller datasets poses a risk of catastrophic forgetting, where the model overfits a specific task domain and loses important knowledge gained during pre-training. Due to this issue, reasoning skills, like compositional generalization and commonsense face problems while evaluating the model.
The existing methods include prompt-tuning, which involves adding tokens or trainable vectors to the input and optimizing their embeddings. This method allows for adaptation to new tasks with minimal data, reducing the risk of catastrophic forgetting. The second method is the NeurAlly-Decomposed Oracles (NADO) algorithm, which provides a middle ground through a smaller transformer model to control the base model without changing its parameters. However, questions remain about its optimal training practices for significant distribution discrepancies and reducing additional costs associated with training the NADO module. The last method is the GeLaTo Algorithm, an innovative framework to enhance autoregressive text generation by integrating tractable probabilistic models (TPMs).
A team of researchers from the University of California, Los Angeles, Amazon AGI, and Samsung Research America have introduced norm-Disentangled NeurAlly-Decomposed Oracles (DiNADO), an improved parameterization of the NADO algorithm. It enhances NADO’s convergence during supervised fine-tuning and later stages and focuses on the uniqueness of global parametric optima. The inefficiency of gradient estimation is handled using NADO with sparse signals from the control signal function, showing how to improve sample and gradient estimation efficiency. Moreover, a natural combination of DiNADO with approaches like LoRA enables base model updates through a contrastive formulation and enhances NADO’s model capacity while improving inference-time performance.
The DiNADO is evaluated using two main tasks: Formal Machine Translation (FormalMT) and Lexically Constrained Generation (LCG). For FormalMT, a formal reference and a binary classifier are used to approximate the formality score. The LCG task utilizes the CommonGen dataset, which evaluates compositional generalization abilities and commonsense reasoning of text generation models. The experiments are divided into two parts:
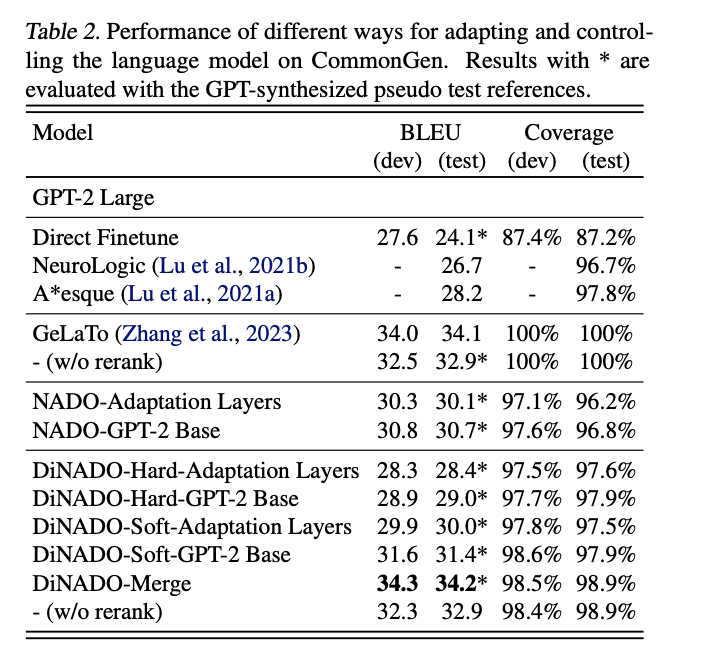
- Results using a GPT-2-Large base distribution, evaluated by generation quality and controllability.
- A sample efficiency study on how different designs and objective reweighting techniques improve NADO’s sample efficiency.
The results demonstrate that DiNADO-Soft outperforms DiNADO-Hard, as the strict forward consistency of DiNADO-Hard can affect the oracle signal’s learning. Larger capacity NADO modules offer enhanced flexibility and controllability with DiNADO-Merge, showing more generalizable performance. Moreover, DiNADO’s norm-disentanglement helps control the regularization term below 0.5, ensuring that updates in the R function consistently improve the composed distribution. This contrasts with vanilla NADO, where divergence in the regularization term can affect performance enhancement, highlighting DiNADO’s superior training dynamics and effectiveness in controlled text generation tasks.
In summary, researchers introduced DiNADO, an enhanced parameterization of the NADO algorithm. One of the main advantages of DiNADO is its compatibility with fine-tuning methods like LoRA, enabling a capacity-rich variant of NADO. Moreover, the researchers conducted a theoretical analysis of the vanilla NADO implementation’s flawed designs and suggested specific solutions. This paper contributes valuable insights and enhancements in the field of controllable language generation, potentially opening new pathways for more efficient and effective text generation applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and LinkedIn. Join our Telegram Channel. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit

Sajjad Ansari is a final year undergraduate from IIT Kharagpur. As a Tech enthusiast, he delves into the practical applications of AI with a focus on understanding the impact of AI technologies and their real-world implications. He aims to articulate complex AI concepts in a clear and accessible manner.