Generative World Models for Enhanced Multi-Agent Decision-Making

Recent developments in generative models have paved the way for innovations in chatbots and picture production, among other areas. These models have demonstrated remarkable performance across a range of tasks, but they frequently falter when faced with intricate, multi-agent decision-making scenarios. This issue is mostly due to generative models’ incapacity to learn by trial and error, which is an essential component of human cognition. Rather than actually experiencing circumstances, they mainly rely on pre-existing facts, which results in inadequate or inaccurate solutions in increasingly complex settings.
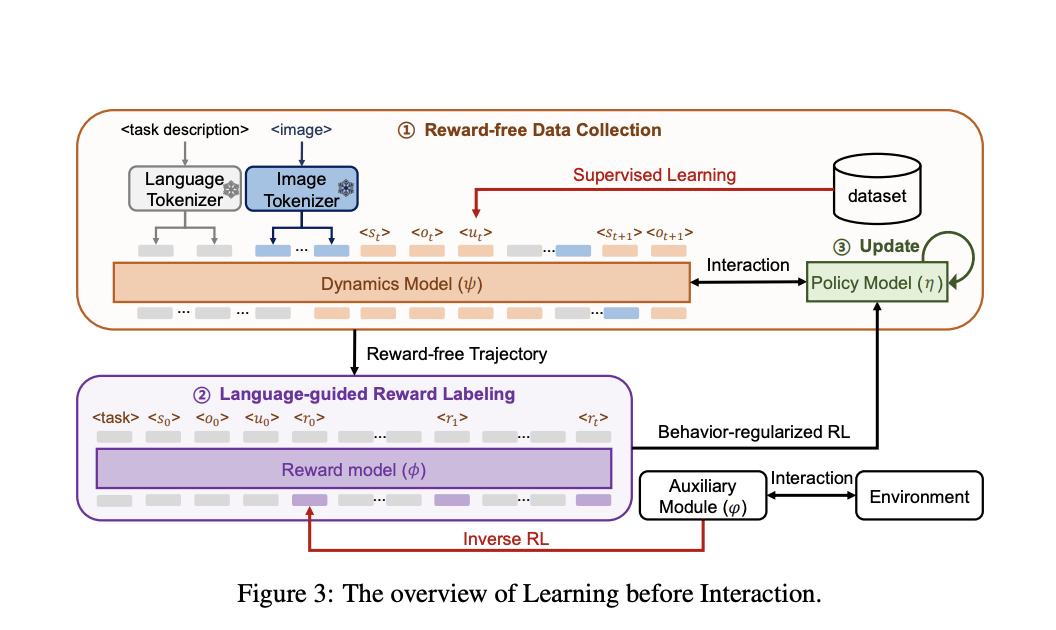
A unique method has been developed to overcome this limitation, including a language-guided simulator in the multi-agent reinforcement learning (MARL) framework. This paradigm seeks to enhance the decision-making process through simulated experiences, hence improving the quality of the generated solutions. The simulator functions as a world model that can pick up on two essential concepts: reward and dynamics. While the reward model assesses the results of those acts, the dynamics model forecasts how the environment will change in response to various activities.
A causal transformer and an image tokenizer make up the dynamics model. The causal transformer creates interaction transitions in an autoregressive way, while the picture tokenizer transforms visual input into a structured format that the model can analyze. In order to simulate how agents interact over time, the model predicts each step in the interaction sequence based on steps that have come before it. Conversely, a bidirectional transformer has been used in the reward model. The training process for this component involves optimizing the probability of expert demonstrations, which serve as training examples of optimal behavior. The reward model gains the ability to link particular activities to rewards by using plain-language task descriptions as a guide.
In practical terms, the world model may simulate agent interactions and produce a series of images that depict the result of those interactions when given an image of the environment as it is at that moment and a task description. The world model is used to train the policy, which controls the agents’ behavior, until it converges, indicating that it has discovered an efficient method for the given job. The model’s solution to the decision-making problem is the resulting image sequence, which visually depicts the task’s progression.
According to empirical findings, this paradigm considerably enhances the quality of solutions for multi-agent decision-making issues. It has been evaluated on the well-known StarCraft Multi-Agent Challenge benchmark, which is used to assess MARL systems. The framework works well on activities it was trained on and also did a good job of generalizing to new, untrained tasks.
One of this approach’s main advantages is its capacity to produce consistent interaction sequences. This indicates that the model generates logical and coherent results when it imitates agent interactions, resulting in more trustworthy decision-making. Furthermore, the model can clearly explain why particular behaviors were rewarded, which is essential for comprehending and enhancing the decision-making process. This is because the reward functions are explicable at each interaction stage.
The team has summarized their primary contributions as follows,
- New MARL Datasets for SMAC: Based on a given state, a parser automatically generates ground-truth images and task descriptions for the StarCraft Multi-Agent Challenge (SMAC). This work has presented new datasets for SMAC.
- The study has introduced Learning before Interaction (LBI), an interactive simulator that improves multi-agent decision-making by generating high-quality answers through trial-and-error experiences.
- Superior Performance: Based on empirical findings, LBI performs better on training and unseen tasks than different offline learning techniques. The model provides Transparency in decision-making, which creates consistent imagined paths and offers explicable rewards for every interaction state.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit
[Upcoming Event- Oct 17 202] RetrieveX – The GenAI Data Retrieval Conference (Promoted)
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.