Orthogonal Paths: Simplifying Jailbreaks in Language Models

Ensuring the safety and ethical behavior of large language models (LLMs) in responding to user queries is of paramount importance. Problems arise from the fact that LLMs are designed to generate text based on user input, which can sometimes lead to harmful or offensive content. This paper investigates the mechanisms by which LLMs refuse to generate certain types of content and develops methods to improve their refusal capabilities.
Currently, LLMs use various methods to refuse user requests, such as inserting refusal phrases or using specific templates. However, these methods are often ineffective and can be bypassed by users who attempt to manipulate the models. The proposed solution by the researchers from ETH Zürich, Anthropic, MIT and others involve a novel approach called “weight orthogonalization,” which ablates the refusal direction in the model’s weights. This method is designed to make the refusal more robust and difficult to bypass.
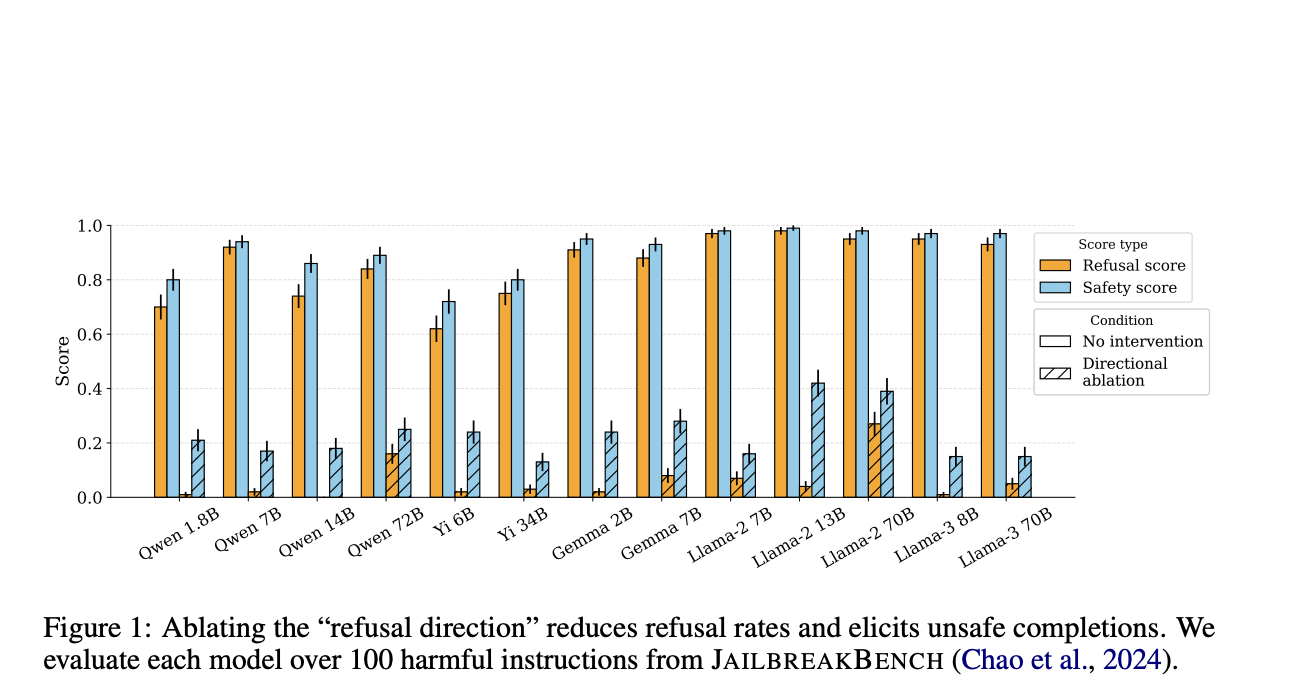
Weight orthogonalization technique is simpler and more efficient than existing methods as it does not require gradient-based optimization or a dataset of harmful completions. The weight orthogonalization method involves adjusting the weights in the model so that the direction associated with refusals is orthogonalized, effectively preventing the model from following refusal directives while maintaining its original capabilities. It is based on the concept of directional ablation, an inference-time intervention where the component corresponding to the refusal direction is zeroed out in the model’s residual stream activations. In this approach, the researchers modify the weights directly to achieve the same effect.
By orthogonalizing matrices like the embedding matrix, positional embedding matrix, attention-out matrices, and MLP out matrices, the model is prevented from writing to the refusal direction in the first place. This modification ensures the model retains its original capabilities while no longer adhering to the refusal mechanism.
Performance evaluations of this method, conducted using the HARMBENCH test set, show promising results. The attack success rate (ASR) of the orthogonalized models indicates that this method is on par with prompt-specific jailbreak techniques, like GCG, which optimize jailbreaks for individual prompts. The weight orthogonalization method demonstrates high ASR across various models, including the LLAMA-2 and QWEN families, even when the system prompts are designed to enforce safety and ethical guidelines.
While the proposed method significantly simplifies the process of jailbreaking LLMs, it also raises important ethical considerations. The researchers acknowledge that this method marginally lowers the barrier for jailbreaking open-source model weights, potentially enabling misuse. However, they argue that it does not substantially alter the risk profile of open-sourcing models. The work underscores the fragility of current safety mechanisms and calls for a scientific consensus on the limitations of these techniques to inform future policy decisions and research efforts.
This research highlights a critical vulnerability in the safety mechanisms of LLMs and introduces an efficient method to exploit this weakness. The researchers demonstrate a simple yet powerful technique to bypass refusal mechanisms by orthogonalizing the refusal direction in the model’s weights. This work not only advances the understanding of LLM vulnerabilities but also emphasizes the need for robust and effective safety measures to prevent misuse.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 45k+ ML SubReddit
Shreya Maji is a consulting intern at MarktechPost. She is pursued her B.Tech at the Indian Institute of Technology (IIT), Bhubaneswar. An AI enthusiast, she enjoys staying updated on the latest advancements. Shreya is particularly interested in the real-life applications of cutting-edge technology, especially in the field of data science.