Researchers from China Introduce Video-LLaVA: A Simple but Powerful Large Visual-Language Baseline Model
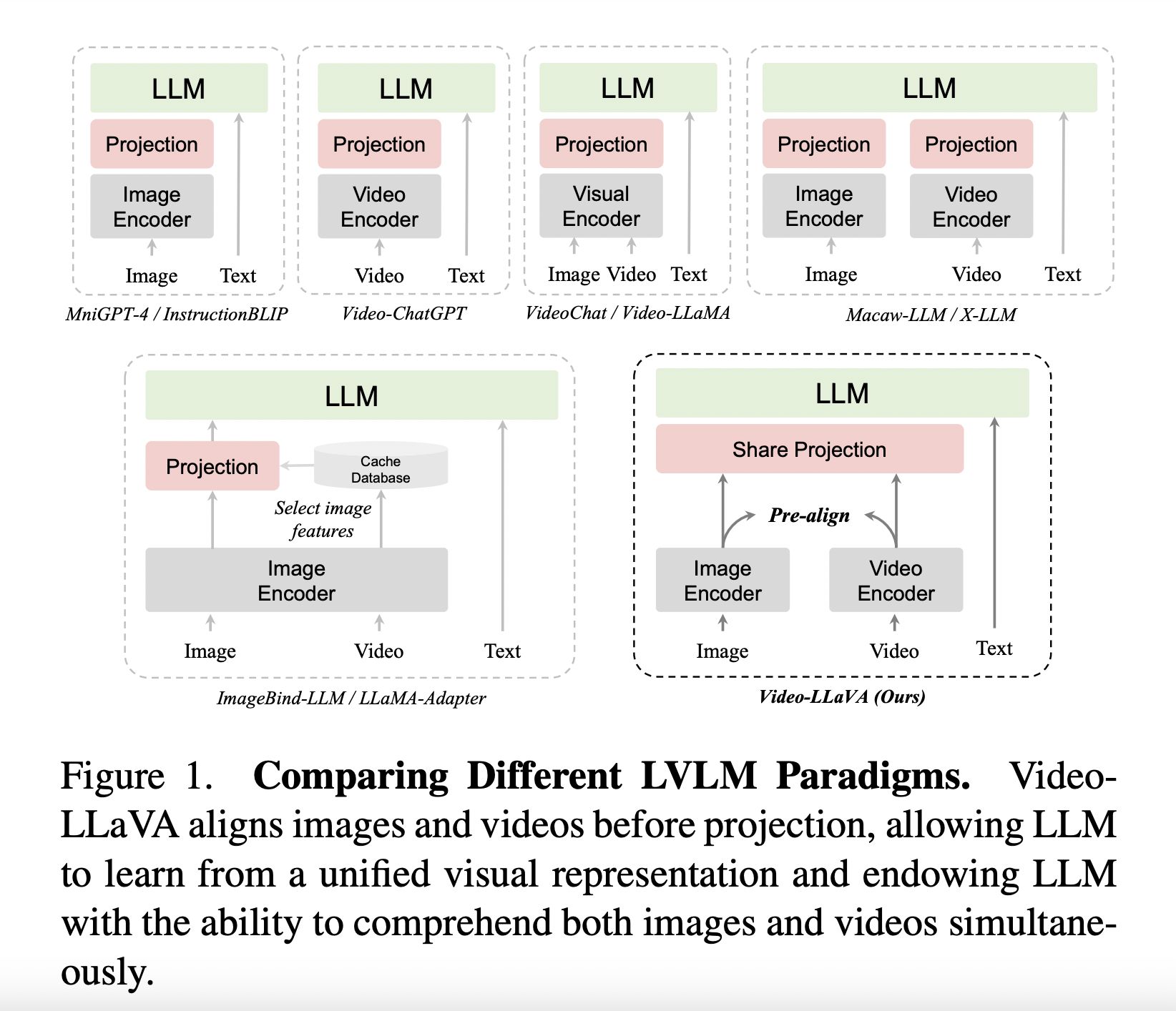

Researchers from Peking University, Peng Cheng Laboratory, Peking University Shenzhen Graduate School, and Sun Yat-sen University introduce the Large Vision-Language Model (LVLM) approach, Video-LLaVA, unifying visual representation into the language feature space. Unlike existing methods that encode images and videos separately, Video-LLaVA achieves a unified LVLM by addressing misalignment issues during projection. This simple yet robust model outperforms benchmarks on nine image datasets, excelling in image question-answering across five datasets and four toolkits.
Video-LLaVA integrates images and videos into a single feature space, improving multi-modal interactions. It outperforms Video-ChatGPT on various image benchmarks and excels in image question-answering. In video understanding, Video-LLaVA consistently surpasses Video-ChatGPT and outperforms the state-of-the-art Chat-UniVi on multiple video datasets. Leveraging the reasoning capabilities of an LLM, Video-LLaVA is trained using Vicuna-7B v1.5 and visual encoders derived from LanguageBind and ViT-L14.
Addressing misalignment challenges in existing approaches that encode images and videos separately, it introduces Video-LLaVA, a unified vision-language model. This model aligns visual representations of images and videos before projection, mitigating issues for LLMs to learn multi-modal interactions. Video-LLaVA surpasses advanced LVLMs and Video-ChatGPT in various image and video benchmarks, showcasing improved performance in understanding and responding to human-provided instructions. The approach highlights the benefits of aligning visual features into a unified space before projection for enhanced multi-modal interaction learning.
Video-LLaVA aligns visual representations of images and videos into a unified feature space before projection. It employs Vicuna-7B v1.5 as the language model, with visual encoders derived from LanguageBind, initialized by ViT-L14. The training process involves resizing and cropping images to 224×224. Utilizing a subset of 558K LAION-CC-SBU image-text pairs from CC3M for understanding pretraining. Instructional datasets are sourced from various places, including a 665K image-text instruction dataset from LLaVA v1.5 and a 100K video-text instruction dataset from Video-ChatGPT.
Video-LLaVA excels on nine image benchmarks, outperforming Video-ChatGPT on MSRVTT, MSVD, TGIF, and ActivityNet by 5.8%, 9.9%, 18.6%, and 10.1%, respectively. It performs on 89 image benchmarks, surpassing InstructBLIP-7B in question-answering. Competing favorably with more powerful LVLMs, it exceeds InstructBLIP-13B by 14.7 on VisWiz. Video-LLaVA significantly enhances video question-answering across four datasets, showcasing its capability to understand and learn from images and videos through a unified visual representation.
In conclusion, Video-LLaVA is an exceptionally large visual-language model that effectively addresses misalignment issues and performs better on diverse image benchmarks. Its joint training on images and videos enhances its proficiency, allowing it to surpass expert models specifically designed for images or videos. The model’s remarkable comprehension of unified visual concepts and excellent performance in image question-answering benchmarks demonstrate the effectiveness of its harmonious visual training framework, highlighting its powerful capabilities.
Future research could explore advanced alignment techniques before projection to enhance LVLMs in multi-modal interactions. Alternative approaches to unifying tokenization for images and videos should be investigated to address misalignment challenges. Evaluating Video-LLaVA on additional benchmarks and datasets would assess its generalizability. Comparisons with larger language models could elucidate scalability and potential enhancements. Enhancing the computational efficiency of Video-LLaVA and investigating the impact of joint training on LVLM performance are avenues for further exploration.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.