This AI Paper from the University of Washington Proposes Cross-lingual Expert Language Models (X-ELM): A New Frontier in Overcoming Multilingual Model Limitations

Large-scale multilingual language models are the foundation of many cross-lingual and non-English Natural Language Processing (NLP) applications. These models are trained on massive volumes of text in multiple languages. However, the drawback to their widespread use is that because numerous languages are modeled in a single model, there is competition for the limited capacity of the model. This, thereby, results in lower performance in individual languages as compared to monolingual models. This problem, known as the curse of multilingualism, primarily affects languages with little resources.
To overcome the prevalent problem of multilingual language models (LMs) performing worse than monolingual ones due to inter-language competition for model parameters., a team of researchers from the University of Washington, Charles University in Prague, and the Allen Institute for Artificial Intelligence has suggested Cross-lingual Expert Language Models (X-ELM) as a solution. This approach includes training language models separately on portions of a multilingual corpus.
The main goal of X-ELM is to reduce the inter-language conflict for model parameters by enabling autonomous specialization of each language model in the ensemble on a particular subset of the multilingual data. This method aims to preserve the ensemble’s efficiency while adjusting each model’s level of proficiency to a certain language.
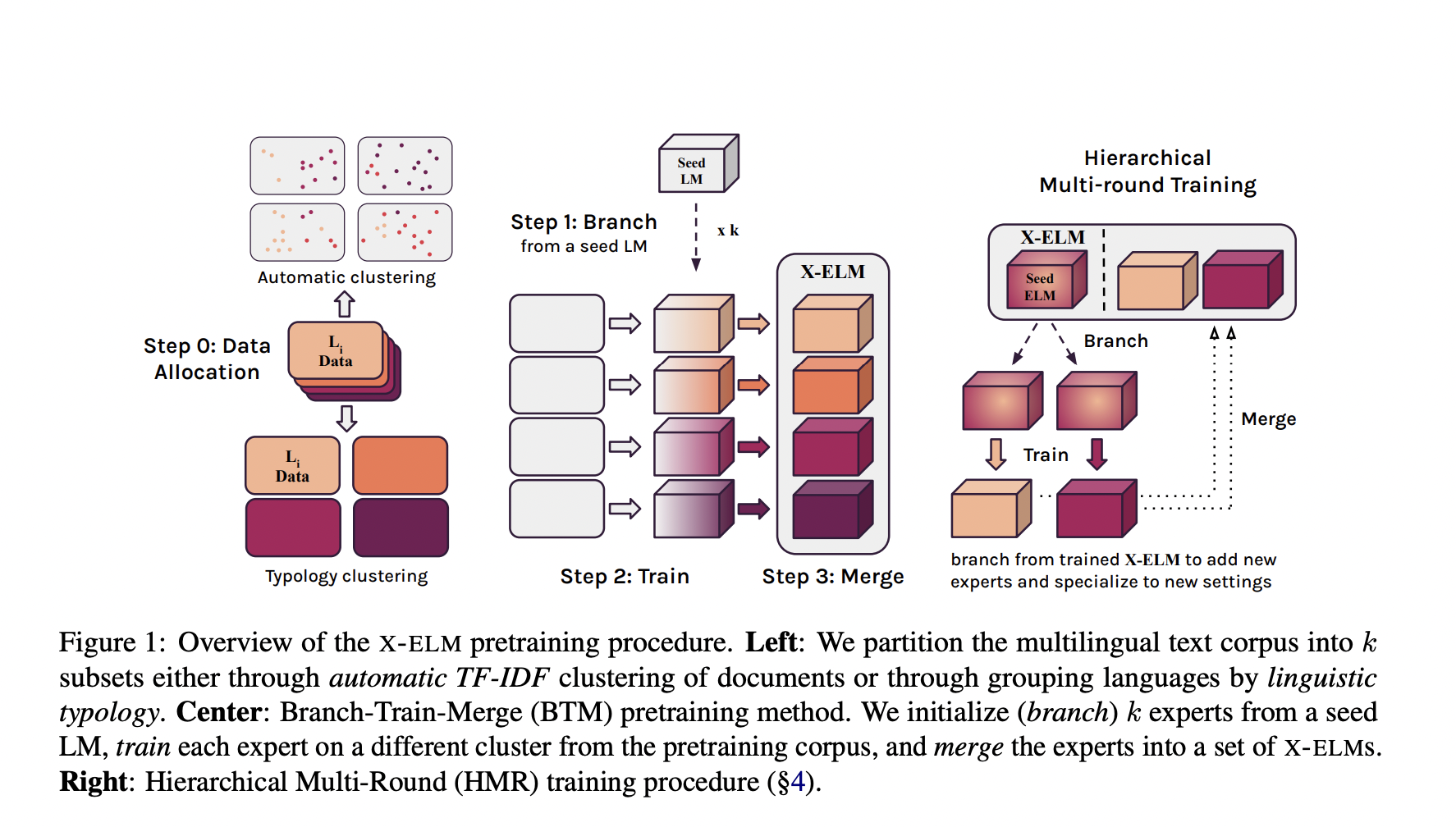
The team has shared that independent training has been done on a different subset of a multilingual corpus for every X-ELM. By using an ensemble technique, the model capacity has been scaled effectively to reflect all of the corpus’s languages more accurately. The team has also presented x-BTM, an expansion of the Branch-Train-Merge (BTM) paradigm designed for the more heterogeneous multilingual environment, in order to train X-ELMs.
x-BTM enhances current BTM methods by introducing a balanced multilingual data clustering approach based on typological similarity. It also includes Hierarchical Multi-Round training (HMR), a technique that effectively educates new experts with specialized knowledge of previously undiscovered languages or other multilingual data distributions.
The research paper released by the team shows that experts can be dynamically selected for inference once the first X-ELMs are trained. Further rounds of x-BTM on new experts branching from current X-ELMs allow the models to be adjusted to new situations, expanding the total X-ELM set without changing the existing experts.
Twenty languages have been used in the experiments, and four new languages have been adapted to show that X-ELMs perform better in different experimental conditions than dense language models with the same compute budget. The increases in perplexity seen in X-ELM languages have been distributed evenly throughout language resourcedness. The HMR training has proven to be a more efficient means of adapting the models to new languages than traditional language-adaptive pretraining techniques.
The studies have shown that X-ELM performs better than jointly trained, multilingual models in all languages taken into consideration when given the same computational resources. Its performance improvements also apply to downstream operations, demonstrating the model’s usefulness in real-world scenarios. The model can also adjust to new languages without suffering from catastrophic forgetting of previously learned languages thanks to its iterative capability of adding new experts to the ensemble.
In conclusion, this research perfectly addresses the difficulties in using massive multilingual language models (LMs) and presents cross-lingual expert language models (X-ELM) as a potential solution.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.